After 2 years of slow but steady development, we would like to announce the first preview release of native GPU programming capabilities for Julia. You can now write your CUDA kernels in Julia, albeit with some restrictions, making it possible to use Julia's high-level language features to write high-performance GPU code.
The programming support we're demonstrating here today consists of the low-level building blocks, sitting at the same abstraction level of CUDA C. You should be interested if you know (or want to learn) how to program a parallel accelerator like a GPU, while dealing with tricky performance characteristics and communication semantics.
You can easily add GPU support to your Julia installation (see below for detailed instructions) by installing CUDAnative.jl. This package is built on top of experimental interfaces to the Julia compiler, and the purpose-built LLVM.jl and CUDAdrv.jl packages to compile and execute code. All this functionality is brand-new and thoroughly untested, so we need your help and feedback in order to improve and finalize the interfaces before Julia 1.0.
How to get started
CUDAnative.jl is tightly integrated with the Julia compiler and the underlying LLVM framework, which complicates version and platform compatibility. For this preview we only support Julia 0.6 built from source, on Linux or macOS. Luckily, installing Julia from source is well documented in the main repository's README. Most of the time it boils down to the following commands:
$ git clone https://github.com/JuliaLang/julia.git
$ cd julia
$ git checkout v0.6.0-pre.alpha # or any later tag
$ make # add -jN for N parallel jobs
$ ./juliaFrom the Julia REPL, installing CUDAnative.jl and its dependencies is just a matter of using the package manager. Do note that you need to be using the NVIDIA binary driver, and have the CUDA toolkit installed.
Pkg.add("CUDAnative")
# Optional: test the package
Pkg.test("CUDAnative")At this point, you can start writing kernels and execute them on the GPU using CUDAnative's @cuda! Be sure to check out the examples, or continue reading for a more textual introduction.
"Hello World" Vector addition
A typical small demo of GPU programming capabilities (think of it as the GPU Hello World) is to perform a vector addition. The snippet below does exactly that using Julia and CUDAnative.jl:
using CUDAdrv, CUDAnative
function kernel_vadd(a, b, c)
# from CUDAnative: (implicit) CuDeviceArray type,
# and thread/block intrinsics
i = (blockIdx().x-1) * blockDim().x + threadIdx().x
c[i] = a[i] + b[i]
return nothing
end
dev = CuDevice(0)
ctx = CuContext(dev)
# generate some data
len = 512
a = rand(Int, len)
b = rand(Int, len)
# allocate & upload on the GPU
d_a = CuArray(a)
d_b = CuArray(b)
d_c = similar(d_a)
# execute and fetch results
@cuda (1,len) kernel_vadd(d_a, d_b, d_c) # from CUDAnative.jl
c = Array(d_c)
using Base.Test
@test c == a + b
destroy(ctx)How does it work?
Most of this example does not rely on CUDAnative.jl, but uses functionality from CUDAdrv.jl. This package makes it possible to interact with CUDA hardware through user-friendly wrappers of CUDA's driver API. For example, it provides an array type CuArray, takes care of memory management, integrates with Julia's garbage collector, implements @elapsed using GPU events, etc. It is meant to form a strong foundation for all interactions with the CUDA driver, and does not require a bleeding-edge version of Julia. A slightly higher-level alternative is available under CUDArt.jl, building on the CUDA runtime API instead, but hasn't been integrated with CUDAnative.jl yet.
Meanwhile, CUDAnative.jl takes care of all things related to native GPU programming. The most significant part of that is generating GPU code, and essentially consists of three phases:
interfacing with Julia: repurpose the compiler to emit GPU-compatible LLVM IR (no calls to CPU libraries, simplified exceptions, ...)
interfacing with LLVM (using LLVM.jl): optimize the IR, and compile to PTX
interfacing with CUDA (using CUDAdrv.jl): compile PTX to SASS, and upload it to the GPU
All this is hidden behind the call to @cuda, which generates code to compile our kernel upon first use. Every subsequent invocation will re-use that code, convert and upload arguments[1], and finally launch the kernel. And much like we're used to on the CPU, you can introspect this code using runtime reflection:
# CUDAnative.jl provides alternatives to the @code_ macros,
# looking past @cuda and converting argument types
julia> CUDAnative.@code_llvm @cuda (1,len) kernel_vadd(d_a, d_b, d_c)
define void @julia_kernel_vadd_68711 {
[LLVM IR]
}
# ... but you can also invoke without @cuda
julia> @code_ptx kernel_vadd(d_a, d_b, d_c)
.visible .func julia_kernel_vadd_68729(...) {
[PTX CODE]
}
# or manually specify types (this is error prone!)
julia> code_sass(kernel_vadd, (CuDeviceArray{Float32,2},CuDeviceArray{Float32,2},CuDeviceArray{Float32,2}))
code for sm_20
Function : julia_kernel_vadd_68481
[SASS CODE]Another important part of CUDAnative.jl are the intrinsics: special functions and macros that provide functionality hard or impossible to express using normal functions. For example, the {thread,block,grid}{Idx,Dim} functions provide access to the size and index of each level of work. Local shared memory can be created using the @cuStaticSharedMem and @cuDynamicSharedMem macros, while @cuprintf can be used to display a formatted string from within a kernel function. Many math functions are also available; these should be used instead of similar functions in the standard library.
What is missing?
As I've already hinted, we don't support all features of the Julia language yet. For example, it is currently impossible to call any function from the Julia C runtime library (aka. libjulia.so). This makes dynamic allocations impossible, cripples exceptions, etc. As a result, large parts of the standard library are unavailable for use on the GPU. We will obviously try to improve this in the future, but for now the compiler will error when it encounters unsupported language features:
julia> nope() = println(42)
nope (generic function with 1 method)
julia> @cuda (1,1) nope()
ERROR: error compiling nope: emit_builtin_call for REPL[1]:1 requires the runtime language feature, which is disabledAnother big gap is documentation. Most of CUDAnative.jl mimics or copies CUDA C, while CUDAdrv.jl wraps the CUDA driver API. But we haven't documented what parts of those APIs are covered, or how the abstractions behave, so you'll need to refer to the examples and tests in the CUDAnative and CUDAdrv repositories.
Another example: parallel reduction
For a more complex example, let's have a look at a parallel reduction for Kepler-generation GPUs. This is a typical well-optimized GPU implementation, using fast communication primitives at each level of execution. For example, threads within a warp execute together on a SIMD-like core, and can share data through each other's registers. At the block level, threads are allocated on the same core but don't necessarily execute together, which means they need to communicate through core local memory. Another level up, only the GPU's DRAM memory is a viable communication medium.
The Julia version of this algorithm looks pretty similar to the CUDA original: this is as intended, because CUDAnative.jl is a counterpart to CUDA C. The new version is much more generic though, specializing both on the reduction operator and value type. And just like we're used to with regular Julia code, the @cuda macro will just-in-time compile and dispatch to the correct specialization based on the argument types.
So how does it perform? Turns out, pretty good! The chart below compares the performance of both the CUDAnative.jl and CUDA C implementations[2], using BenchmarkTools.jl to measure the execution time. The small constant overhead (note the logarithmic scale) is due to a deficiency in argument passing, and will be fixed.
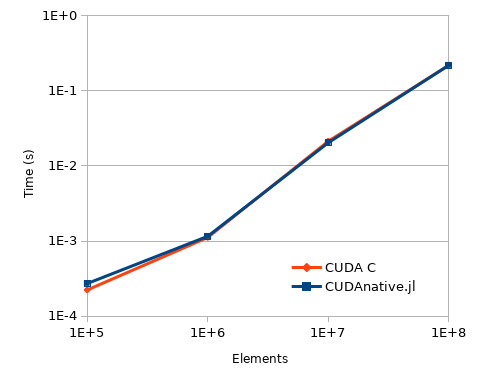
| [2] | The measurements include memory transfer time, which is why a CPU implementation was not included (realistically, data would be kept on the GPU as long as possible, making it an unfair comparison). |
{kind=link}
cuda-memcheck to detect out-of-bound accesses $ cuda-memcheck julia examples/oob.jl
========= CUDA-MEMCHECK
========= Invalid __global__ write of size 4
========= at 0x00000148 in examples/oob.jl:14:julia_memset_66041
========= by thread (10,0,0) in block (0,0,0)
========= Address 0x1020b000028 is out of boundscuda-gdb and friends will not work very well.
Try it out!
If you have experience with GPUs or CUDA development, or maintain a package which could benefit from GPU acceleration, please have a look or try out CUDAnative.jl! We need all the feedback we can get, in order to prioritize development and finalize the infrastructure before Julia hits 1.0.
I want to help
Even better! There's many ways to contribute, for example by looking at the issues trackers of the individual packages making up this support:
Each of those packages are also in perpetual need of better API coverage, and documentation to cover and explain what has already been implemented.
Thanks
This work would not have been possible without Viral Shah and Alan Edelman arranging my stay at MIT. I'd like to thank everybody at Julia Central and around, it has been a blast! I'm also grateful to Bjorn De Sutter, and IWT Vlaanderen, for supporting my time at Ghent University.
| [1] | See the README for a note on how expensive this currently is. |